
In the rapidly evolving field of artificial intelligence, the demand for computational power required for model training is growing exponentially, leading to a computational power gap that is becoming one of the key factors constraining model development. Decentralized P2P model training, with its unique advantages, is very likely to be an important direction for solving this problem in the future.
Prime Intellect, a forward-looking company in the field of artificial intelligence, has released a highly anticipated AI model distributed training framework that supports global distribution—OpenDiLoCo. The birth of this framework brings new ideas and methods to solve the computational power dilemma.
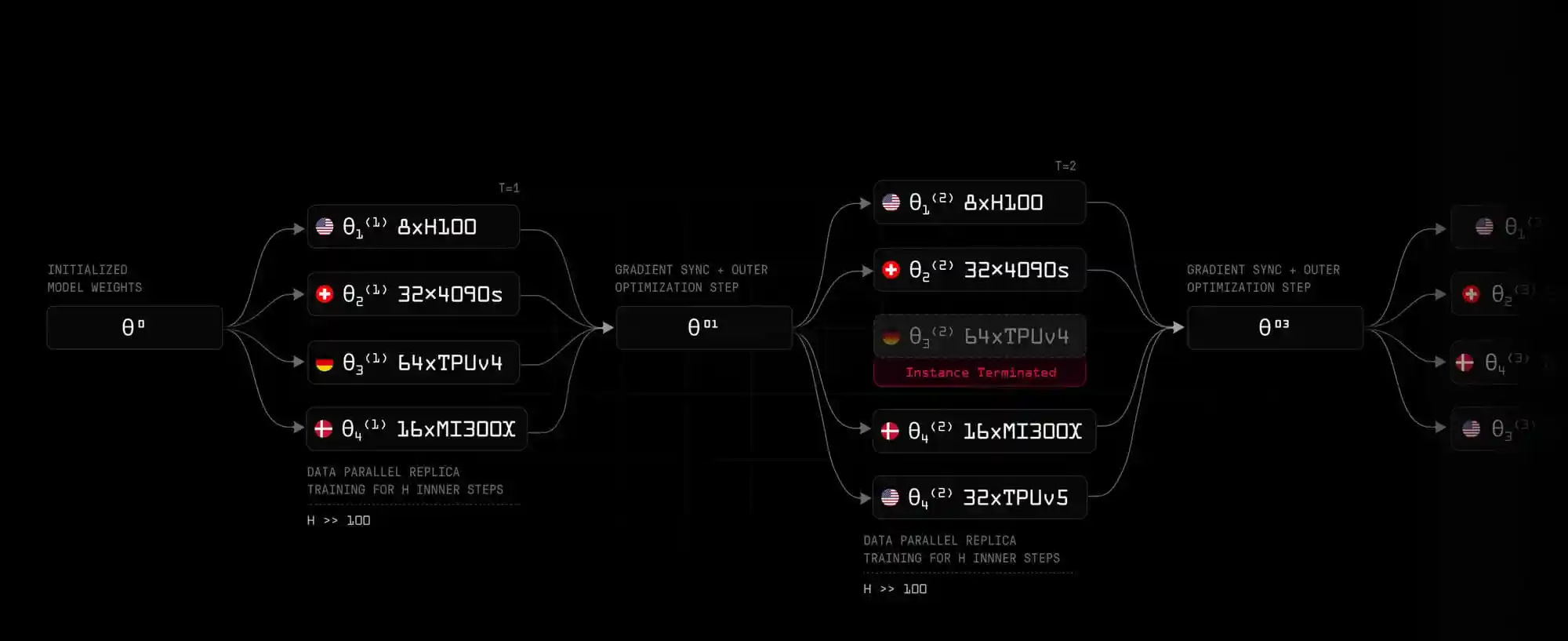
To verify the feasibility and effectiveness of the OpenDiLoCo framework, the research team at Prime Intellect meticulously designed and implemented a challenging experiment using this framework. They selected three different countries as experimental sites, connecting these geographically dispersed computing resources through the network to jointly train a model.
In the experiment, it was pleasantly surprising that the utilization rate of computing resources reached an impressive 90-95%. This means that the framework can efficiently integrate and utilize dispersed computing resources to maximize their effectiveness. Moreover, the research team also successfully expanded the training scale to three times the original working scale, fully demonstrating the strong scalability of the OpenDiLoCo framework. Through this experiment, it was powerfully proven that the framework is very effective for training models with billions of parameters.
The OpenDiLoCo framework has achieved such excellent results thanks to its unique design and advanced technological concepts. It is based on Google DeepMind's distributed low communication (DiLoCo) method, which lays a solid foundation for the efficient operation of the framework.
OpenDiLoCo has several notable features. First is the dynamic adjustment of computing resources, which can allocate and adjust computing resources in real-time according to the actual needs of the training tasks, ensuring that every computing resource plays its role at the most appropriate time and place, thereby improving the efficiency of the entire training process. Second is the fault-tolerant training mechanism, which can effectively deal with issues such as computing node failures or network instability in the complex distributed computing environment, ensuring that the training process is not interrupted by individual node failures and that the training tasks can continue stably. Lastly, and most crucially, is its peer-to-peer architecture. Unlike traditional architectures with a master node, OpenDiLoCo has no master node, making communication between computing nodes more equal and direct, avoiding bottlenecks that may occur at the master node and affecting the entire training process, thus further improving training efficiency.
Thanks to the adoption of the DiLoCo method, communication time during training has been greatly reduced. The proportion of full reduction bottlenecks in the entire training time is only 6.9%, which is extremely small and almost negligible to the overall training speed. This means that the OpenDiLoCo framework can ensure efficient use of computing resources while minimizing the impact of communication time on training speed, thereby achieving fast and stable model training.