
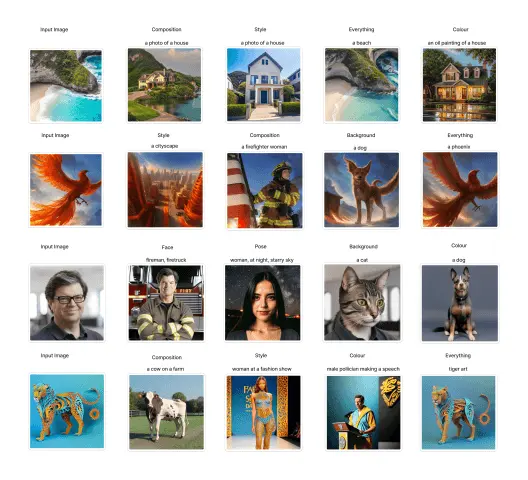
Diffusion models have demonstrated outstanding performance in the realm of image generation. However, when it comes to controlling the generation process through text prompts, there are some significant limitations that cannot be overlooked. In practical applications, we have found that text prompts often struggle to precisely describe the style of an image, such as whether it is realistic, abstract, or cartoonish. Additionally, when it comes to fine-grained structures within an image, text prompts fall short, and it is challenging to convey expectations for detailed parts like facial features through simple textual descriptions.
In response to these issues, the IPAdapter - Instruct model has been developed. This model employs an innovative approach by explicitly specifying user intentions within instruction prompts, thereby achieving efficient multi-task training. Not only does this training method allow the model to be effectively trained on multiple tasks, but it also surprisingly maintains the high performance characteristic of single-task models.
The core technology of the IPAdapter - Instruct model lies in its ability to compress multiple adapters into a combination of prompts and images. This unique design enables the model to handle various complex tasks while maintaining compatibility with the base diffusion model. However, like any technology, it has its developmental bottlenecks. The main limitation lies in the creation process of the training dataset. This process is not only time-consuming but also severely limited by the availability of source data. Since high-quality training data is crucial for model performance, this limitation has, to some extent, affected the model's further development.
Looking to the future, researchers hope to further optimize the model on the existing foundation. Specifically, they aim to integrate pixel-level precise guidance with semantic guidance organically, while continuing to use instruction prompts to accurately convey user intentions. If this goal can be achieved, the model's performance in image generation will be greatly enhanced, better meeting users' needs for generating high-quality images.