
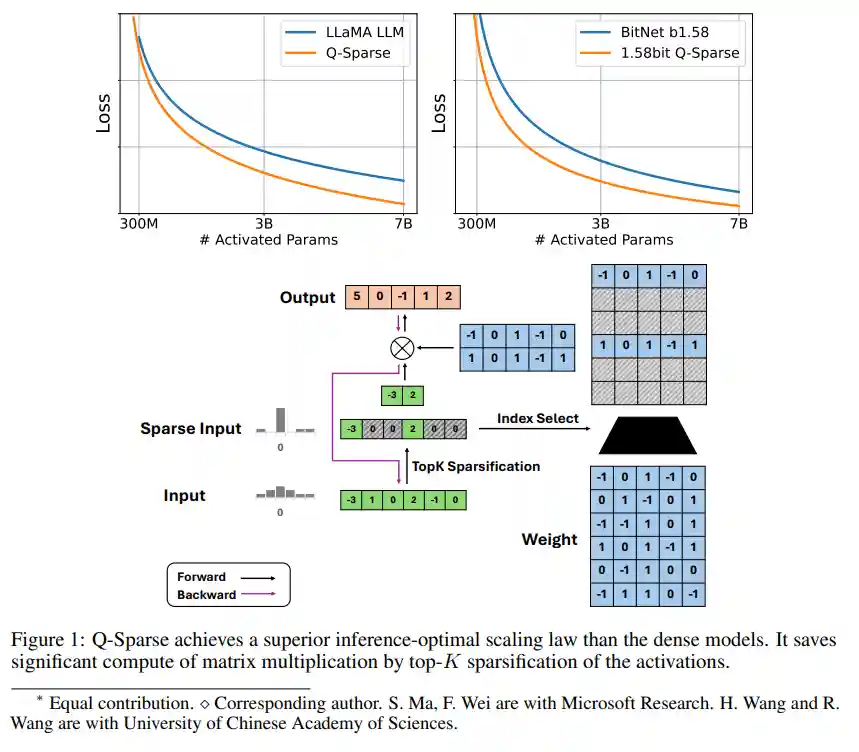
In this highly innovative paper, researchers propose a new method called Q-Sparse, which can make large language models more efficient during the inference process. The main approach is to implement "sparsing" of the model's activation values. Specifically, it means only retaining the most important part of the activation values and setting the rest to zero. In this way, it can greatly reduce the amount of computation and memory usage. Surprisingly, this treatment almost does not affect the performance of the model.
During the research process, researchers also deeply discovered some patterns of sparsified models. For example, they found the optimal sparsity level, providing an important basis for further optimizing the model. They tested this method in a variety of scenarios, including training models from scratch, continuing to train existing models, and fine-tuning. In these different scenarios, the method has achieved satisfactory results. In particular, this method can also be combined with other optimization techniques, such as low-bit quantization. This combination is expected to greatly improve the efficiency of large language models, bringing new breakthroughs and opportunities for the development of large language models.