
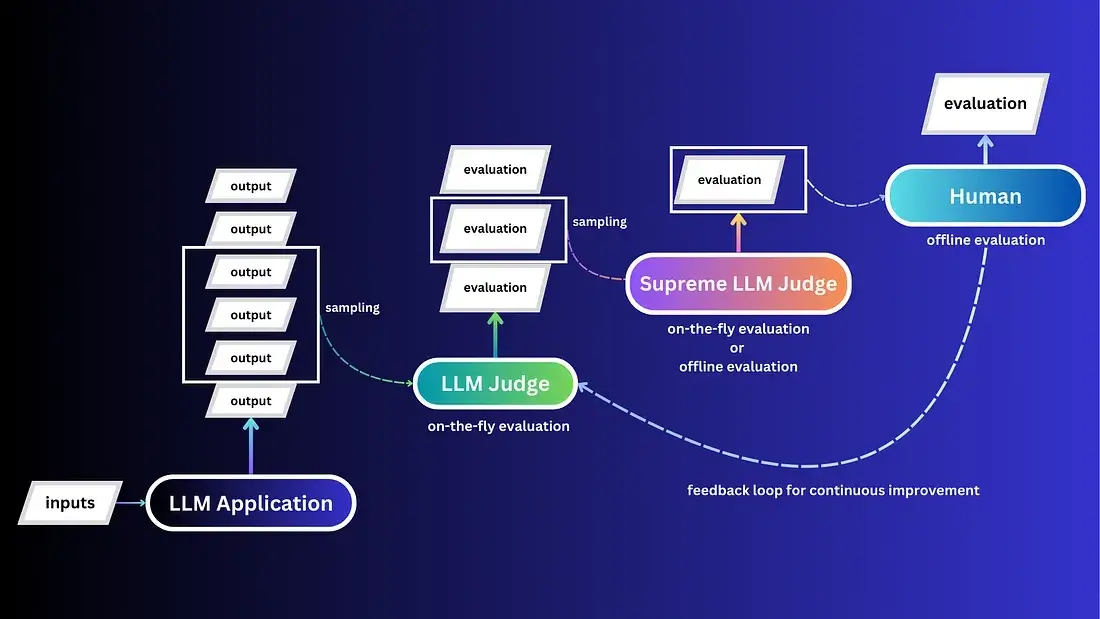
The article is detailed and in-depth, introducing the principles and methods involved in building reliable Large Language Models (LLM) applications. The author, with their rich experience in building multiple LLM systems, has innovatively proposed the LLM Triangle Principle. This principle covers three key aspects: Standard Operating Procedures (SOP), Engineering Techniques, and Contextual Data, and emphasizes Model Selection as an important plus principle.
Firstly, Standard Operating Procedures (SOP) play a crucial role in building reliable LLM applications. It aims to simulate the cognitive process of experts in detail and transform it into a series of clear and explicit steps. These steps can provide precise guidance for the design and implementation of LLM applications. For example, when applying LLM in the medical field, the expert's diagnostic process may involve multiple complex steps, from inquiring and observing patient symptoms, to collecting relevant medical history, to making preliminary judgments on possible diseases, and further examination suggestions. SOP will break down these complex cognitive processes into an orderly process, enabling LLM to process relevant information according to this process, thereby improving the accuracy and reliability of the application.
Secondly, engineering techniques are also an indispensable part of building LLM applications. It mainly involves writing code and designing LLM-Native architecture. In this process, process engineering is a key link. It focuses on how to optimize the entire application process to ensure that information can be efficiently and accurately transmitted between different modules. At the same time, the use of agents is also an important aspect of engineering techniques. Agents can be seen as an intelligent entity with autonomy and interaction capabilities, which can undertake specific tasks in LLM applications, such as information retrieval and result verification. The reasonable use of agents can enhance the functionality and performance of LLM applications.
Furthermore, contextual data is also of great significance for the construction of LLM applications. LLM has the unique characteristic of being a contextual learner, which can adjust its output according to the provided contextual information. How to effectively utilize this characteristic? This requires the help of example learning and retrieval-augmented generation (RAG) technology. Example learning refers to helping LLM better understand and handle specific tasks by providing a large number of relevant examples. For example, in language translation applications, providing a large number of corresponding examples of source language and target language can allow LLM to quickly master the conversion rules between the two languages. Retrieval-augmented generation (RAG) technology is to enhance the generation ability of LLM by retrieving relevant information. When LLM receives a task, it can first retrieve information related to the task, and then generate based on this information, which can improve the accuracy and relevance of the generated content.
Finally, model selection is proposed as a plus principle. When building LLM applications, selecting the right model is crucial. Different models have differences in performance, accuracy, applicable fields, etc. Therefore, it is necessary to comprehensively consider various factors according to specific application needs and choose the most suitable model. For example, for some applications with high real-time requirements, a model with fast response capabilities may be needed; while for some professional field applications with high accuracy requirements, a professional model with good performance in that field may be needed.