
"FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs" introduces a framework designed to enhance natural voice interaction between humans and large language models (LLMs).
- General Overview Core Models: It includes SenseVoice for high-precision multi-language speech recognition, emotion recognition, and audio event detection, as well as CosyVoice for natural voice generation with multi-language, timbre, and emotion control. Open Source Status: The models are open-sourced on Modelscope and Huggingface, with corresponding training, inference, and fine-tuning code released on GitHub.
- SenseVoice Model Functional Overview Multi-language Speech Recognition: Supports over 50 languages, and compared with Whisper on open-source benchmark datasets such as AISHELL-1 and AISHELL-2, SenseVoice-Small adopts a non-autoregressive end-to-end architecture with extremely low inference latency, being 7 times faster than Whisper-Small and 17 times faster than Whisper-Large. Voice Emotion Recognition: Supports recognition of emotions such as Happy, Sad, Angry, and Neutral, and evaluated on 7 popular emotion recognition datasets, SenseVoice-Large can approach or exceed SOTA results on most datasets without target corpus fine-tuning. Audio Event Detection: SenseVoice-Large can predict the start and end positions of audio events, while SenseVoice-Small can detect more events such as coughing, sneezing, etc. Model Architecture: Includes SenseVoice-Small (a fast voice understanding base model with only an encoder) and SenseVoice-Large (an encoder-decoder model that supports more languages for more accurate voice understanding).
- CosyVoice Model Functional Features Multi-language Voice Generation: Can generate voices in multiple languages. Zero-shot Context Generation: Generates content according to prompts in different languages. Style Control: Can control the style of the voice, such as pitch, speaking rate, emotions, etc. Emotion-expressive Voice Generation: Can generate voices with different emotions. Speaker Fine-tuning and Interpolation: Can fine-tune speakers and also perform speaker interpolation. Inference Overview: Voice tokens are generated by an autoregressive transformer, Mel spectrograms are reconstructed based on an ODE-based diffusion model and flow matching, and waveforms are synthesized by HiFTNet vocoder.
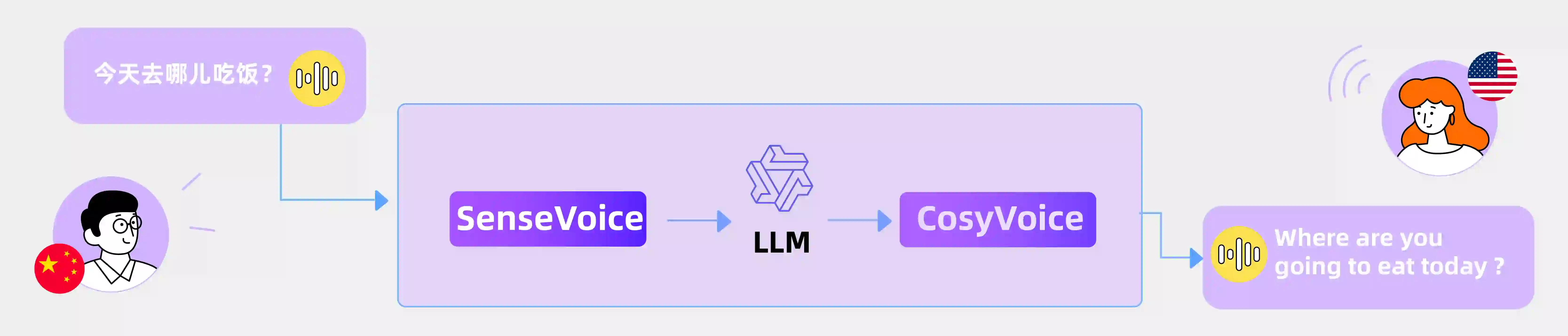
- FunAudioLLM Applications Voice Translation: Integrates SenseVoice, LLMs, and CosyVoice to achieve voice-to-voice translation. Emotional Voice Chat: Develops an emotional voice chat application by integrating the three components, with user and assistant content synthesized by CosyVoice. Interactive Podcasts: Creates interactive podcasts by combining related components. Audiobooks: Utilizes the analytical capabilities of LLMs and the expressive synthesis of CosyVoice to create more expressive audiobooks.