
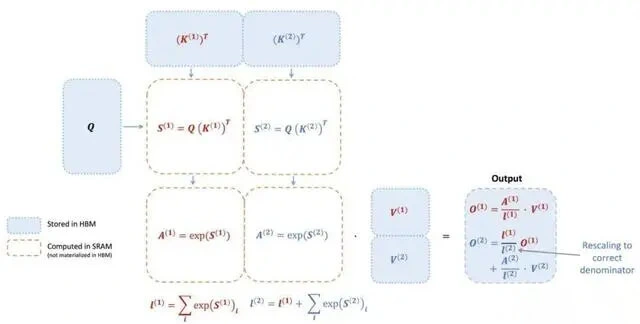
FlashAttention-3, as a highly anticipated technological achievement, has made remarkable enhancements in several key dimensions compared to the previous FlashAttention versions.
- More Efficient GPU Utilization GPU utilization is one of the key factors affecting the training speed and performance of large language models (LLMs). FlashAttention-3 has made significant progress in this area, increasing the training and running speed of LLMs by 1.5 to 2 times compared to previous versions. This means that under the same hardware conditions, using FlashAttention-3 can complete the model training process more quickly, or process input text more efficiently when running the model, thus generating output results faster. This improvement is mainly due to the innovation in algorithm design and optimization of FlashAttention-3, which can better utilize the computing power of GPUs, reduce the waste of computing resources, and ensure that GPUs can focus more on key computing tasks related to model training and operation. For example, when processing large-scale text datasets, FlashAttention-3 can more reasonably allocate GPU memory and computing cores, avoiding issues such as memory overflow or computational bottlenecks, thereby ensuring that the model can be trained and run at a faster pace.
- Better Performance at Lower Precision FlashAttention-3 demonstrates exceptional capability in precision handling. It can use lower precision numbers (FP8) while still maintaining accuracy. In traditional model calculations, higher precision data types are usually required to ensure the accuracy of the results, but this also leads to increased computational costs and slower speeds. FlashAttention-3 breaks this traditional limitation through advanced algorithm optimization and numerical processing techniques. It can effectively avoid the accumulation of computational errors caused by reduced precision, ensuring that the model's output results still have high accuracy. This capability is significant in large-scale language model calculations, as it not only reduces memory usage and improves computational efficiency but also speeds up model training and inference without sacrificing accuracy. For example, when dealing with semantic understanding and generation tasks of long texts, FlashAttention-3 can quickly perform attention mechanism calculations using FP8 precision data, accurately capturing key information in the text, thus generating high-quality output results.
- Ability to Use Longer Contexts in LLMs In the field of natural language processing, context information is crucial for AI models to accurately understand and process text. FlashAttention-3 has made an important breakthrough by accelerating the attention mechanism, enabling LLMs to process longer text segments more effectively. In previous models, due to the computational efficiency limitations of the attention mechanism, models often experienced information loss or inaccurate understanding when processing longer texts. FlashAttention-3 optimizes the computation of the attention mechanism, allowing models to allocate attention and integrate information across various parts of long texts more quickly, thereby better understanding the overall semantics and contextual relationships of the text. This enables AI models to better utilize longer context information when processing various natural language processing tasks, improving the effectiveness of task handling. For example, in text generation tasks, the model can generate more coherent and logical output content based on longer input texts; in machine translation tasks, it can better consider the contextual information of the source language text, thus generating more accurate translation results.